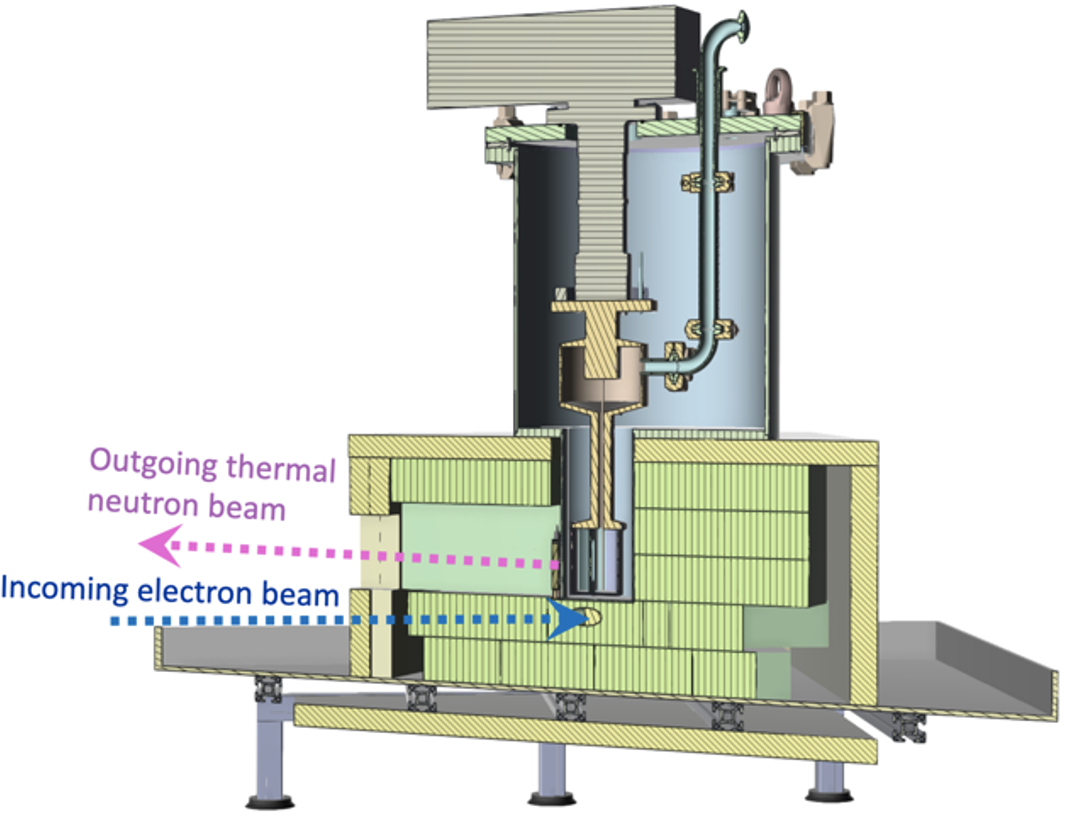
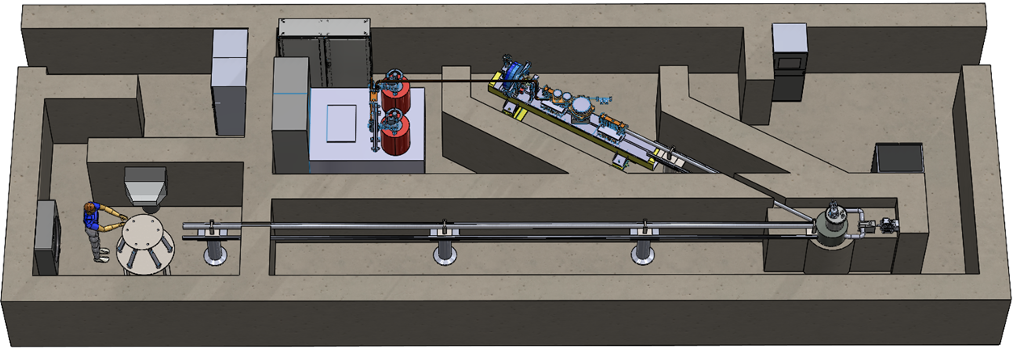
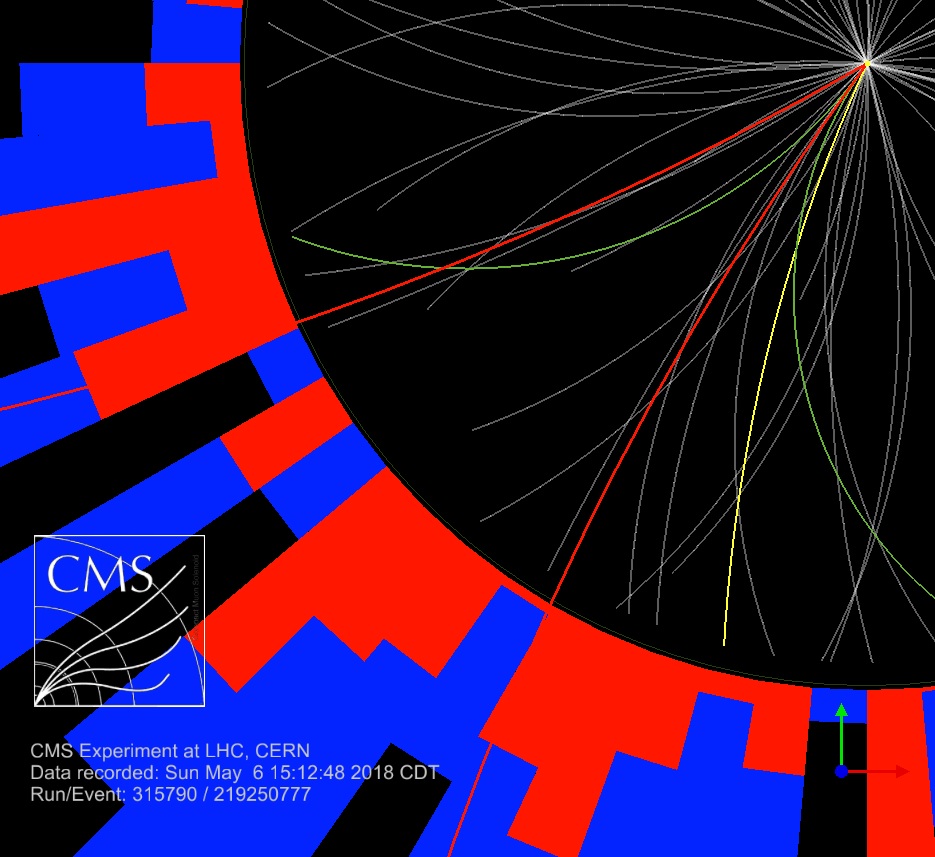
3.4.24
The result has implications for future searches for rare beauty meson decays and for the interpretation of results from the Fermilab g-2 experiment.


The LHCb detector (Credit: Maximilien Brice, CERN)
The LHCb [below] collaboration recently reported the first observation of the decay of the Bc+ meson (composed of two heavy quarks, b and c) into a J/ψ charm-anticharm quark bound state and a pair of pions, π+π0. The decay process shows a contribution from an intermediate particle, a ρ+ meson that forms for a brief moment and then decays into the π+π0 pair.
The Bc+ is the heaviest meson that can only decay through the weak interactions, via the decay of one heavy constituent quark. Bc+ decays into an odd number of light hadrons and a J/ψ (or other charm-anticharm quark bound states, called “charmonia”) have been studied intensively and have been found to be in remarkable agreement with the theoretical expectations. The decay of Bc+ into a J/ψ and a π+π0 pair is the simplest decay into charmonium and an even number of light hadrons. It has never been observed before, mainly because the precise reconstruction of the low-energy π0 meson through its decay into a pair of photons is very challenging in an LHC proton-proton collision environment.
A precise measurement of the Bc+→J/ψπ+π0 decay will allow better understanding of its possible contribution as a background source for the study of other decays of Bc mesons as well as rare decays of B0 mesons. From the theoretical point of view, decays of Bc into J/ψ and an even number of pions are closely related to the decays of the τ lepton into an even number of pions, and to the e+e– annihilation into an even number of pions. Precise measurements of e+e– annihilation into two pions in the ρ mass region (as in the Bc decay discussed here) are crucial for the interpretation of results from the Fermilab g-2 experiment measuring the anomalous magnetic dipole moment of the muon, since low-energy e+e– annihilation into hadrons is an important source of the uncertainty of the g-2 measurements.
The ratio of the probability of the new decay to that of the decay of Bc+ into J/ψπ+ has been calculated by various theorists over the last 30 years. Now these predictions can finally be compared with an experimental measurement: most predictions agree with the new result obtained by LHCb (2.80±0.15±0.11±0.16).
The large number of b-quarks produced in LHC collisions and the excellent detector allows LHCb to study the production, decays and other properties of the Bc+ meson in detail. Since the meson’s discovery by the CDF experiment at the Tevatron collider, 18 new Bc+ decays have been observed (with more than five standard deviations), all of them by LHCb.
Read more in the LHCb paper.
See the full article here .
Comments are invited and will be appreciated, especially if the reader finds any errors which I can correct. Use “Comment” near the bottom of the post.

five-ways-keep-your-child-safe-school-shootings
Please help promote STEM in your local schools.
![]()
Our mission
Knowledge Transfer at CERN (CH) aims to engage with experts in science, technology and industry in order to create opportunities for the transfer of CERN’s technology and know-how. The ultimate goal is to accelerate innovation and maximize the global positive impact of CERN on society. This is done by promoting and transferring the technological and human capital developed at CERN. The CERN KT group promotes CERN as a centre of technological excellence, and promotes the positive impact of fundamental research organizations on society.
“Places like CERN contribute to the kind of knowledge that not only enriches humanity, but also provides the wellspring of ideas that become the technologies of the future.”
Fabiola Gianotti, Director-General of CERN

From Organization européenne pour la recherche nucléaire technologies to society
Below, you can see how CERN’s various areas of expertise translates into impact across industries beyond CERN. Read more about this at the from CERN technologies to society page.



Meet CERN in a variety of places:



THE FOUR MAJOR PROJECT COLLABORATIONS







The LHC magnets surround the beampipe along its 27 km circumference- Image CERN



















CERN FASER is designed to study the interactions of high-energy neutrinos and search for new as-yet-undiscovered light and weakly interacting particles. Such particles are dominantly produced along the beam collision axis and may be long-lived particles, travelling hundreds of metres before decaying. The existence of such new particles is predicted by many models beyond the Standard Model that attempt to solve some of the biggest puzzles in physics, such as the nature of dark matter and the origin of neutrino masses.














The SND@LHC experiment consists of an emulsion/tungsten target for neutrinos (yellow) interleaved with electronic tracking devices (grey), followed downstream by a detector (brown) to identify muons and measure the energy of the neutrinos. (Image: Antonio Crupano/SND@LHC)


These two new collimators have been developed at CERN for the future HL-LHC. These models will be installed at LHC interaction points 1 (ATLAS detector) and 5 (CMS detector) during Long Shutdown 3 (LS3). (Image: CERN)
The European Organization for Nuclear Research, known as CERN (French pronunciation: Conseil européen pour la Recherche nucléaire), is an intergovernmental organization that operates the largest particle physics laboratory in the world. Established in 1954, it is based in Meyrin, western suburb of Geneva, on the France–Switzerland border. It comprises 23 member states. Israel, admitted in 2013, is the only non-European full member. CERN is an official United Nations General Assembly observer.
The acronym CERN is also used to refer to the laboratory; in 2019, it had 2,660 scientific, technical, and administrative staff members, and hosted about 12,400 users from institutions in more than 70 countries. In 2016, CERN generated 49 petabytes of data.
CERN’s main function is to provide the particle accelerators and other infrastructure needed for high-energy physics research – consequently, numerous experiments have been constructed at CERN through international collaborations. CERN is the site of the Large Hadron Collider (LHC), the world’s largest and highest-energy particle collider. The main site at Meyrin hosts a large computing facility, which is primarily used to store and analyze data from experiments, as well as simulate events. As researchers require remote access to these facilities, the lab has historically been a major wide area network hub. CERN is also the birthplace of the World Wide Web.
History
The convention establishing CERN was ratified on 29 September 1954 by 12 countries in Western Europe. The acronym CERN originally represented the French words for Conseil Européen pour la Recherche Nucléaire (‘European Council for Nuclear Research’), which was a provisional council for building the laboratory, established by 12 European governments in 1952. During these early years, the council worked at the University of Copenhagen under the direction of Niels Bohr before moving to its present site near Geneva. The acronym was retained for the new laboratory after the provisional council was dissolved, even though the name changed to the current Organization Européenne pour la Recherche Nucléaire (‘European Organization for Nuclear Research’) in 1954. According to Lew Kowarski, a former director of CERN, when the name was changed, the abbreviation could have become the awkward OERN, and Werner Heisenberg said that this could “still be CERN even if the name is [not]”.
CERN’s first president was Sir Benjamin Lockspeiser. Edoardo Amaldi was the general secretary of CERN at its early stages when operations were still provisional, while the first Director-General (1954) was Felix Bloch.
The laboratory was originally devoted to the study of atomic nuclei, but was soon applied to higher-energy physics, concerned mainly with the study of interactions between subatomic particles. Therefore, the laboratory operated by CERN is commonly referred to as the European laboratory for particle physics (Laboratoire européen pour la physique des particules), which better describes the research being performed there.
Founding members
At the sixth session of the CERN Council, which took place in Paris from 29 June to 1 July 1953, the convention establishing the organization was signed, subject to ratification, by 12 states. The convention was gradually ratified by the 12 founding Member States: Belgium, Denmark, France, the Federal Republic of Germany, Greece, Italy, the Netherlands, Norway, Sweden, Switzerland, the United Kingdom, and Yugoslavia.
Scientific achievements
Several important achievements in particle physics have been made through experiments at CERN. They include:
• 1973: The discovery of neutral currents in the Gargamelle bubble chamber;
• 1983: The discovery of W and Z bosons in the UA1 and UA2 experiments;
• 1989: The determination of the number of light neutrino families at the Large Electron–Positron Collider (LEP) [below] operating on the Z boson peak;
• 1995: The first creation of antihydrogen atoms in the PS210 experiment;
• 1995–2005: Precision measurement of the Z lineshape, based predominantly on LEP data collected on the Z resonance from 1990 to 1995;
• 1999: The discovery of direct CP violation in the NA48 experiment;
• 2000: The Heavy Ion Programme discovered a new state of matter, the Quark Gluon Plasma.
• 2010: The isolation of 38 atoms of antihydrogen;
• 2011: Maintaining antihydrogen for over 15 minutes;
• 2012: A boson with mass around 125 GeV/c2 consistent with the long-sought Higgs boson.
______________________________
Higgs




______________________________
In September 2011, CERN attracted media attention when the OPERA Collaboration reported the detection of possibly faster-than-light neutrinos. Further tests showed that the results were flawed due to an incorrectly connected GPS synchronization cable.
The 1984 Nobel Prize for Physics was awarded to Carlo Rubbia and Simon van der Meer for the developments that resulted in the discoveries of the W and Z bosons.
The 1992 Nobel Prize for Physics was awarded to CERN staff researcher Georges Charpak “for his invention and development of particle detectors, in particular the multiwire proportional chamber”.
The 2013 Nobel Prize for Physics was awarded to François Englert and Peter Higgs for the theoretical description of the Higgs mechanism in the year after the Higgs boson was found by CERN experiments.
CERN pioneered the introduction of Internet technology, beginning in the early 1980s. This played an influential role in the adoption of the TCP/IP in Europe.
The World Wide Web began as a project at CERN initiated by Tim Berners-Lee in 1989.
This stemmed from his earlier work on a database named ENQUIRE. Robert Cailliau became involved in 1990.
Berners-Lee and Cailliau were jointly honoured by the Association for Computing Machinery in 1995 for their contributions to the development of the World Wide Web. A copy of the original first webpage, created by Berners-Lee, is still published on the World Wide Web Consortium’s website as a historical document.
Based on the concept of hypertext, the project was designed to facilitate the sharing of information between researchers. The first website was activated in 1991. On 30 April 1993, CERN announced that the World Wide Web would be free to anyone.
It became the dominant way through which most users interact with the Internet.
More recently, CERN has become a facility for the development of “grid computing”, hosting projects including the Enabling Grids for E-sciencE (EGEE) and LHC Computing Grid. It also hosts the CERN Internet Exchange Point (CIXP), one of the two main internet exchange points in Switzerland.
As of 2022, CERN employs ten times more engineers and technicians than research physicists.
Particle accelerators
Current complex
CERN operates a network of seven accelerators and two decelerators, and some additional small accelerators. Each machine in the chain increases the energy of particle beams before delivering them to experiments or to the next more powerful accelerator (the decelerators naturally decrease the energy of particle beams before delivering them to experiments or further accelerators/decelerators).
Before an experiment is able to use the network of accelerators, it must be approved by the various Scientific Committees of CERN. As of 2022 active machines are the LHC accelerator and:
• The LINAC 3 linear accelerator generating low energy particles. It provides heavy ions at 4.2 MeV/u for injection into the Low Energy Ion Ring (LEIR).
• The Low Energy Ion Ring (LEIR) accelerates the ions from the ion linear accelerator LINAC 3, before transferring them to the Proton Synchrotron (PS). This accelerator was commissioned in 2005, after having been reconfigured from the previous Low Energy Antiproton Ring (LEAR).
• The Linac4 linear accelerator accelerates negative hydrogen ions to an energy of 160 MeV. The ions are then injected to the Proton Synchrotron Booster (PSB) where both electrons are then stripped from each of the hydrogen ions and thus only the nucleus containing one proton remains. The protons are then used in experiments or accelerated further in other CERN accelerators. Linac4 serves as the source of all proton beams for CERN experiments.
• The Proton Synchrotron Booster increases the energy of particles generated by the proton linear accelerator before they are transferred to the other accelerators.
• The 28 GeV Proton Synchrotron (PS), built during 1954–1959 and still operating as a feeder to the more powerful SPS and to many of CERN’s experiments.
• The Super Proton Synchrotron (SPS), a circular accelerator with a diameter of 2 kilometres built in a tunnel, which started operation in 1976. It was designed to deliver an energy of 300 GeV and was gradually upgraded to 450 GeV. As well as having its own beamlines for fixed-target experiments (currently COMPASS and NA62), it has been operated as a proton–antiproton collider (the SppS collider), and for accelerating high energy electrons and positrons which were injected into the Large Electron–Positron Collider (LEP). Since 2008, it has been used to inject protons and heavy ions into the Large Hadron Collider (LHC).
• The On-Line Isotope Mass Separator (ISOLDE), which is used to study unstable nuclei. The radioactive ions are produced by the impact of protons at an energy of 1.0–1.4 GeV from the Proton Synchrotron Booster. It was first commissioned in 1967 and was rebuilt with major upgrades in 1974 and 1992.
• The Antiproton Decelerator (AD), which reduces the velocity of antiprotons to about 10% of the speed of light for research of antimatter. The AD machine was reconfigured from the previous Antiproton Collector (AC) machine.
• The Extra Low Energy Antiproton ring (ELENA), which takes antiprotons from AD and decelerates them into low energies (speeds) for use in antimatter experiments.
• The AWAKE experiment, which is a proof-of-principle plasma wakefield accelerator.
• The CERN Linear Electron Accelerator for Research (CLEAR) accelerator research and development facility.
Many activities at CERN currently involve operating the Large Hadron Collider (LHC) and the experiments for it. The LHC represents a large-scale, worldwide scientific cooperation project.
The LHC tunnel is located 100 metres underground, in the region between Geneva International Airport and the nearby Jura mountains. The majority of its length is on the French side of the border. It uses the 27 km circumference circular tunnel previously occupied by the Large Electron–Positron Collider (LEP), which was shut down in November 2000. CERN’s existing PS/SPS accelerator complexes are used to pre-accelerate protons and lead ions which are then injected into the LHC.
Eight experiments (CMS, ATLAS, LHCb, MoEDAL, TOTEM, LHCf, FASER and ALICE) are located along the collider; each of them studies particle collisions from a different aspect, and with different technologies.
Construction for these experiments required an extraordinary engineering effort. For example, a special crane was rented from Belgium to lower pieces of the CMS detector into its cavern, since each piece weighed nearly 2,000 tons. The first of the approximately 5,000 magnets necessary for construction was lowered down a special shaft at 13:00 GMT on 7 March 2005.
The LHC has begun to generate vast quantities of data, which CERN streams to laboratories around the world for distributed processing (making use of a specialized grid infrastructure, the LHC Computing Grid).
During April 2005, a trial successfully streamed 600 MB/s to seven different sites across the world.
The initial particle beams were injected into the LHC August 2008. The first beam was circulated through the entire LHC on 10 September 2008, but the system failed 10 days later because of a faulty magnet connection, and it was stopped for repairs on 19 September 2008.
The LHC resumed operation on 20 November 2009 by successfully circulating two beams, each with an energy of 3.5 teraelectronvolts (TeV).
The challenge for the engineers was then to line up the two beams so that they smashed into each other. This is like “firing two needles across the Atlantic and getting them to hit each other” according to Steve Myers, director for accelerators and technology.
On 30 March 2010, the LHC successfully collided two proton beams with 3.5 TeV of energy per proton, resulting in a 7 TeV collision energy. However, this was just the start of what was needed for the expected discovery of the Higgs boson. When the 7 TeV experimental period ended, the LHC revved to 8 TeV (4 TeV per proton) starting March 2012, and soon began particle collisions at that energy. In July 2012, CERN scientists announced the discovery of a new sub-atomic particle that was later confirmed to be the Higgs boson.
In March 2013, CERN announced that the measurements performed on the newly found particle allowed it to conclude that it was a Higgs boson. In early 2013, the LHC was deactivated for a two-year maintenance period, to strengthen the electrical connections between magnets inside the accelerator and for other upgrades.
On 5 April 2015, after two years of maintenance and consolidation, the LHC restarted for a second run. The first ramp to the record-breaking energy of 6.5 TeV was performed on 10 April 2015. In 2016, the design collision rate was exceeded for the first time. A second two-year period of shutdown begun at the end of 2018.
Accelerators under construction
As of October 2019, the construction is on-going to upgrade the LHC’s luminosity in a project called High Luminosity LHC (HL–LHC).

This project should see the LHC accelerator upgraded by 2026 to an order of magnitude higher luminosity.
As part of the HL–LHC upgrade project, also other CERN accelerators and their subsystems are receiving upgrades. Among other work, the LINAC 2 linear accelerator injector was decommissioned and replaced by a new injector accelerator, the LINAC4.
Decommissioned accelerators
• The original linear accelerator LINAC 1. Operated 1959–1992.
• The LINAC 2 linear accelerator injector. Accelerated protons to 50 MeV for injection into the Proton Synchrotron Booster (PSB). Operated 1978–2018.
• The 600 MeV Synchro-Cyclotron (SC) which started operation in 1957 and was shut down in 1991. Was made into a public exhibition in 2012–2013.
• The Intersecting Storage Rings (ISR), an early collider built from 1966 to 1971 and operated until 1984.
• The Super Proton–Antiproton Synchrotron (SppS), operated 1981–1991. A modification of Super Proton Synchrotron (SPS) to operate as a proton-antiproton collider.
• The Large Electron–Positron Collider (LEP), which operated 1989–2000 and was the largest machine of its kind, housed in a 27 km-long circular tunnel which now houses the Large Hadron Collider.
• The LEP Pre-Injector (LPI) accelerator complex,[96] consisting of two accelerators, a linear accelerator called LEP Injector Linac (LIL; itself consisting of two back-to-back linear accelerators called LIL V and LIL W) and a circular accelerator called Electron Positron Accumulator (EPA). The purpose of these accelerators was to inject positron and electron beams into the CERN accelerator complex (more precisely, to the Proton Synchrotron), to be delivered to LEP after many stages of acceleration. Operational 1987–2001; after the shutdown of LEP and the completion of experiments that were directly fed by the LPI, the LPI facility was adapted to be used for the CLIC Test Facility 3 (CTF3).
• The Low Energy Antiproton Ring (LEAR) was commissioned in 1982. LEAR assembled the first pieces of true antimatter, in 1995, consisting of nine atoms of antihydrogen. It was closed in 1996, and superseded by the Antiproton Decelerator. The LEAR apparatus itself was reconfigured into the Low Energy Ion Ring (LEIR) ion booster.
• The Antiproton Accumulator (AA), built 1979–1980, operations ended in 1997 and the machine was dismantled. Stored antiprotons produced by the Proton Synchrotron (PS) for use in other experiments and accelerators (for example the ISR, SppS and LEAR). For later half of its working life operated in tandem with Antiproton Collector (AC), to form the Antiproton Accumulation Complex (AAC).
• The Antiproton Collector (AC), built 1986–1987, operations ended in 1997 and the machine was converted into the Antiproton Decelerator (AD), which is the successor machine for Low Energy Antiproton Ring (LEAR). Operated in tandem with Antiproton Accumulator (AA) and the pair formed the Antiproton Accumulation Complex (AAC), whose purpose was to store antiprotons produced by the Proton Synchrotron (PS) for use in other experiments and accelerators, like the Low Energy Antiproton Ring (LEAR) and Super Proton–Antiproton Synchrotron (SppS).
• The Compact Linear Collider Test Facility 3 (CTF3), which studied feasibility for the future normal conducting linear collider project (the CLIC collider). In operation 2001–2016. One of its beamlines has been converted, from 2017 on, into the new CERN Linear Electron Accelerator for Research (CLEAR) facility.
Possible future accelerators
CERN, in collaboration with groups worldwide, is investigating two main concepts for future accelerators: A linear electron-positron collider with a new acceleration concept to increase the energy (CLIC) and a larger version of the LHC, a project currently named Future Circular Collider.




The smaller accelerators are on the main Meyrin site (also known as the West Area), which was originally built in Switzerland alongside the French border, but has been extended to span the border since 1965. The French side is under Swiss jurisdiction and there is no obvious border within the site, apart from a line of marker stones.
The SPS and LEP/LHC tunnels are almost entirely outside the main site, and are mostly buried under French farmland and invisible from the surface. However, they have surface sites at various points around them, either as the location of buildings associated with experiments or other facilities needed to operate the colliders such as cryogenic plants and access shafts. The experiments are located at the same underground level as the tunnels at these sites.
Three of these experimental sites are in France, with ATLAS in Switzerland, although some of the ancillary cryogenic and access sites are in Switzerland. The largest of the experimental sites is the Prévessin site, also known as the North Area, which is the target station for non-collider experiments on the SPS accelerator. Other sites are the ones which were used for the UA1, UA2 and the LEP experiments (the latter are used by LHC experiments).
Outside of the LEP and LHC experiments, most are officially named and numbered after the site where they were located. For example, NA32 was an experiment looking at the production of so-called “charmed” particles and located at the Prévessin (North Area) site while WA22 used the Big European Bubble Chamber (BEBC) at the Meyrin (West Area) site to examine neutrino interactions. The UA1 and UA2 experiments were considered to be in the Underground Area, i.e. situated underground at sites on the SPS accelerator.
Most of the roads on the CERN Meyrin and Prévessin sites are named after famous physicists, such as Wolfgang Pauli, who pushed for CERN’s creation. Other notable names are Richard Feynman, Albert Einstein, and Bohr.
Participation and funding
Member states and budget
Since its foundation by 12 members in 1954, CERN regularly accepted new members. All new members have remained in the organization continuously since their accession, except Spain and Yugoslavia. Spain first joined CERN in 1961, withdrew in 1969, and rejoined in 1983. Yugoslavia was a founding member of CERN but quit in 1961. Of the 23 members, Israel joined CERN as a full member on 6 January 2014, becoming the first (and currently only) non-European full member.
The budget contributions of member states are computed based on their GDP.
Enlargement
Associate Members, Candidates:
• Turkey signed an association agreement on 12 May 2014 and became an associate member on 6 May 2015.
• Pakistan signed an association agreement on 19 December 2014 and became an associate member on 31 July 2015.
• Cyprus signed an association agreement on 5 October 2012 and became an associate member in the pre-stage to membership on 1 April 2016.
• Ukraine signed an association agreement on 3 October 2013. The agreement was ratified on 5 October 2016.
• India signed an association agreement on 21 November 2016. The agreement was ratified on 16 January 2017.
• Slovenia was approved for admission as an Associate Member state in the pre-stage to membership on 16 December 2016. The agreement was ratified on 4 July 2017.
• Lithuania was approved for admission as an Associate Member state on 16 June 2017. The association agreement was signed on 27 June 2017 and ratified on 8 January 2018.
• Croatia was approved for admission as an Associate Member state on 28 February 2019. The agreement was ratified on 10 October 2019.
• Estonia was approved for admission as an Associate Member in the pre-stage to membership state on 19 June 2020. The agreement was ratified on 1 February 2021.
• Latvia and CERN signed an associate membership agreement on 14 April 2021. Latvia was formally admitted as an Associate Member on 2 August 2021.
International relations
Three countries have observer status:
• Japan – since 1995
• Russia – since 1993 (suspended as of March 2022)
• United States – since 1997
Also observers are the following international organizations:
• UNESCO – since 1954
• European Commission – since 1985
• JINR – since 2014 (suspended as of March 2022)
Non-Member States (with dates of Co-operation Agreements) currently involved in CERN programmes are:
• Albania – October 2014
• Algeria – 2008
• Argentina – 11 March 1992
• Armenia – 25 March 1994
• Australia – 1 November 1991
• Azerbaijan – 3 December 1997
• Bangladesh – 2014
• Belarus – 28 June 1994 (suspended as of March 2022)
• Bolivia – 2007
• Bosnia & Herzegovina – 16 February 2021
• Brazil – 19 February 1990 & October 2006
• Canada – 11 October 1996
• Chile – 10 October 1991
• China – 12 July 1991, 14 August 1997 & 17 February 2004
• Colombia – 15 May 1993
• Costa Rica – February 2014
• Ecuador – 1999
• Egypt – 16 January 2006
• Georgia – 11 October 1996
• Iceland – 11 September 1996
• Iran – 5 July 2001
• Jordan – 12 June 2003 MoU with Jordan and SESAME, in preparation of a cooperation agreement signed in 2004.
• Kazakhstan – June 2018
• Lebanon – 2015
• Malta – 10 January 2008
• Mexico – 20 February 1998
• Mongolia – 2014
• Montenegro – 12 October 1990
• Morocco – 14 April 1997
• Nepal – 19 September 2017
• New Zealand – 4 December 2003
• North Macedonia – 27 April 2009
• Palestine – December 2015
• Paraguay – January 2019
• Peru – 23 February 1993
• Philippines – 2018
• Qatar – 2016
• Republic of Korea (South Korea) – 25 October 2006
• Saudi Arabia – 2006
• South Africa – 4 July 1992
• Sri Lanka – February 2017
• Thailand – 2018
• Tunisia – May 2014
• United Arab Emirates – 2006
• Vietnam – 2008
CERN also has scientific contacts with the following other countries:
• Bahrain
• Cuba
• Ghana
• Honduras
• Hong Kong
• Indonesia
• Ireland
• Kuwait
• Luxemburg
• Madagascar
• Malaysia
• Mauritius
• Morocco
• Mozambique
• Oman
• Rwanda
• Singapore
• Sudan
• Taiwan
• Tanzania
• Uzbekistan
• Zambia
International research institutions, such as CERN, can aid in science diplomacy.
Associated institutions
A large number of institutes around the world are associated to CERN through current collaboration agreements and/or historical links. The list below contains organizations represented as observers to the CERN Council, organizations to which CERN is an observer and organizations based on the CERN model:
• European Molecular Biology Laboratory, organization based on the CERN model
• European Space Research Organization (since 1975 ESA), organization based on the CERN model
• European Southern Observatory, organization based on the CERN model
• JINR, observer to CERN Council, CERN is represented in the JINR Council. JINR is currently suspended, due to the CERN Council Resolution of 25 March 2022.
• SESAME, CERN is an observer to the SESAME Council
• UNESCO, observer to CERN Council
.cern
.cern is a top-level domain for CERN. It was registered on 13 August 2014. On 20 October 2015 CERN moved its main Website to https://home.cern.
Open Science
The Open Science movement focuses on making scientific research openly accessible and on creating knowledge through open tools and processes. Open access, open data, open source software and hardware, open licenses, digital preservation and reproducible research are primary components of open science and areas in which CERN has been working towards since its formation.
CERN has developed a number of policies and official documents that enable and promote open science, starting with CERN’s founding convention in 1953 which indicated that all its results are to be published or made generally available. Since then, CERN published its open access policy in 2014, which ensures that all publications by CERN authors will be published with gold open access and most recently an open data policy that was endorsed by the four main LHC collaborations (ALICE, ATLAS, CMS and LHCb).
The open data policy complements the open access policy, addressing the public release of scientific data collected by LHC experiments after a suitable embargo period. Prior to this open data policy, guidelines for data preservation, access and reuse were implemented by each collaboration individually through their own policies which are updated when necessary.
The European Strategy for Particle Physics, a document mandated by the CERN Council that forms the cornerstone of Europe’s decision-making for the future of particle physics, was last updated in 2020 and affirmed the organization’s role within the open science landscape by stating: “The particle physics community should work with the relevant authorities to help shape the emerging consensus on open science to be adopted for publicly-funded research, and should then implement a policy of open science for the field”.
Beyond the policy level, CERN has established a variety of services and tools to enable and guide open science at CERN, and in particle physics more generally. On the publishing side, CERN has initiated and operates a global cooperative project, the Sponsoring Consortium for Open Access Publishing in Particle Physics, SCOAP3, to convert scientific articles in high-energy physics to open access. Currently, the SCOAP3 partnership represents 3000+ libraries from 44 countries and 3 intergovernmental organizations who have worked collectively to convert research articles in high-energy physics across 11 leading journals in the discipline to open access.
Public-facing results can be served by various CERN-based services depending on their use case: the CERN Open Data portal, Zenodo, the CERN Document Server, INSPIRE and HEPData are the core services used by the researchers and community at CERN, as well as the wider high-energy physics community for the publication of their documents, data, software, multimedia, etc.
CERN’s efforts towards preservation and reproducible research are best represented by a suite of services addressing the entire physics analysis lifecycle (such as data, software and computing environment). CERN Analysis Preservation helps researchers to preserve and document the various components of their physics analyses; REANA (Reusable Analyses) enables the instantiating of preserved research data analyses on the cloud.
All of the above mentioned services are built using open source software and strive towards compliance with best effort principles where appropriate and where possible, such as the FAIR principles, the FORCE11 guidelines and Plan S, while at the same time taking into account relevant activities carried out by the European Commission.
Public exhibits
The Globe of Science and Innovation, which opened in late 2005, is open to the public. It is used four times a week for special exhibits.
The Microcosm museum previously hosted another on-site exhibition on particle physics and CERN history. It closed permanently on 18 September 2022, in preparation for the installation of the exhibitions in Science Gateway.
CERN also provides daily tours to certain facilities such as the Synchro-cyclotron (CERNs first particle accelerator) and the superconducting magnet workshop.
In 2004, a two-meter statue of the Nataraja, the dancing form of the Hindu god Shiva, was unveiled at CERN. The statue, symbolizing Shiva’s cosmic dance of creation and destruction, was presented by the Indian government to celebrate the research center’s long association with India. A special plaque next to the statue explains the metaphor of Shiva’s cosmic dance with quotations from physicist Fritjof Capra:
Hundreds of years ago, Indian artists created visual images of dancing Shivas in a beautiful series of bronzes. In our time, physicists have used the most advanced technology to portray the patterns of the cosmic dance. The metaphor of the cosmic dance thus unifies ancient mythology, religious art and modern physics.
Arts at CERN
CERN launched its Cultural Policy for engaging with the arts in 2011. The initiative provided the essential framework and foundations for establishing Arts at CERN, the arts programme of the Laboratory.
Since 2012, Arts at CERN has fostered creative dialogue between art and physics through residencies, art commissions, exhibitions and events. Artists across all creative disciplines have been invited to CERN to experience how fundamental science pursues the big questions about our universe.
Even before the arts programme officially started, several highly regarded artists visited the Laboratory, drawn to physics and fundamental science. As early as 1972, James Lee Byars was the first artist to visit the Laboratory and the only one, so far, to feature on the cover of the CERN Courier. Mariko Mori, Gianni Motti, Cerith Wyn Evans, John Berger and Anselm Kiefer are among the artists who came to CERN in the years that followed.
The programmes of Arts at CERN are structured according to their values and vision to create bridges between cultures. Each programme is designed and formed in collaboration with cultural institutions, other partner laboratories, countries, cities and artistic communities eager to connect with CERN’s research, support their activities, and contribute to a global network of art and science.
They comprise research-led artistic residencies that take place on-site or remotely. More than 200 artists from 80 countries have participated in the residencies to expand their creative practices at the Laboratory, benefiting from the involvement of 400 physicists, engineers and CERN staff. Between 500 and 800 applications are received every year. The programmes comprise Collide, the international residency programme organised in partnership with a city; Connect, a programme of residencies to foster experimentation in art and science at CERN and in scientific organizations worldwide in collaboration with Pro Helvetia, and Guest Artists, a short stay for artists to stay to engage with CERN’s research and community.
In popular culture
• The band Les Horribles Cernettes was founded by women from CERN. The name was chosen so to have the same initials as the LHC.
• The science journalist Katherine McAlpine made a rap video called Large Hadron Rap about CERN’s Large Hadron Collider with some of the facility’s staff.
• Particle Fever, a 2013 documentary, explores CERN throughout the inside and depicts the events surrounding the 2012 discovery of the Higgs Boson [ https://www.youtube.com/watch?v=5Lx109jdGCc ].
• John Titor, a self-proclaimed time traveler, alleged that CERN would invent time travel in 2001.
• CERN is depicted in the visual novel/anime series Steins;Gate as SERN, a shadowy organization that has been researching time travel in order to restructure and control the world.
• In Robert J. Sawyer’s 1999 science fiction novel Flashforward, as CERN’s Large Hadron Collider accelerator is performing a run to search for the Higgs boson the entire human race sees themselves twenty-one years and six months in the future.
• A number of conspiracy theories feature CERN, accusing the organization of partaking in occult rituals and secret experiments involving opening portals into Hell or other dimensions, shifting the world into an alternative timeline and causing earthquakes.
• In Dan Brown’s 2000 mystery-thriller novel Angels & Demons and 2009 film of the same name, a canister of antimatter is stolen from CERN.
• CERN is depicted in a 2009 episode of South Park (Season 13, Episode 6), Pinewood Derby. Randy Marsh, the father of one of the main characters, breaks into the “Hadron Particle Super Collider in Switzerland” and steals a “superconducting bending magnet created for use in tests with particle acceleration” to use in his son Stan’s Pinewood Derby racer.
• In the 2010 season 3 episode 15 of the TV situation comedy The Big Bang Theory, The Large Hadron Collision, Leonard and Raj travel to CERN to attend a conference and see the LHC.
• The 2012 student film Decay, which centers on the idea of the Large Hadron Collider transforming people into zombies, was filmed on location in CERN’s maintenance tunnels.
• The Compact Muon Solenoid at CERN was used as the basis for the Megadeth’s Super Collider album cover.
• CERN forms part of the back story of the massively multiplayer augmented reality game Ingress, and in the 2018 Japanese anime television series Ingress: The Animation, based on Niantic’s augmented reality mobile game of the same name.
• In 2015, Sarah Charley, US communications manager for LHC experiments at CERN with graduate students Jesse Heilman of the University of California-Riverside, and Tom Perry and Laser Seymour Kaplan of the University of Wisconsin-Madison created a parody video based on Collide, a song by American artist Howie Day. The lyrics were changed to be from the perspective of a proton in the Large Hadron Collider. After seeing the parody, Day re-recorded the song with the new lyrics, and released a new version of Collide in February 2017 with a video created during his visit to CERN.
• In 2015, Ryoji Ikeda created an art installation called Supersymmetry based on his experience as a resident artist at CERN.
• The television series Mr. Robot features a secretive, underground project apparatus that resembles the ATLAS experiment.
• Parallels, a Disney+ television series released in March 2022, includes a particle-physics laboratory at the French-Swiss border called “ERN”. Various accelerators and facilities at CERN are referenced during the show, including ATLAS, CMS, the Antiproton Decelerator, and the FCC.


 The ATLAS detector at CERN. (Maximilien Brice/CERN)
The ATLAS detector at CERN. (Maximilien Brice/CERN)